-
Surf Bikes!
On a few occasions I’ve been fortunate enough to live within biking distance of a surf break. One of my favorite activities to do in this situation is outfit a bicycle with a surfboard rack and use it for transportation to the beach.
Here are the bikes. PVC construction inspired by http://www.rodndtube.com/surf/info/surf_racks/BicycleSurfboardRack.shtml.
GT Karakoram – 2007

I got this bicycle for free when I purchased my first mountain bike from someone on Craigslist in Glendale in late 2006. I took both bicycles back to Westwood via bus where I was promptly stopped and questioned by the police as to why I had two bikes with me on the bus. Neither showed up as reported missing so they let me out. The next year I moved to Santa Monica near Wilshire and 17th Street and built this rack so I could ride to Venice Beach to surf in the morning. The ride was long and the waves were bad but I enjoyed every minute of it.
In 2008 I moved too far from the coast for this to be practical so I donated the bicycle to Bikerowave and didn’t put another one together for ~10 years.
-
Prop 13 wtf
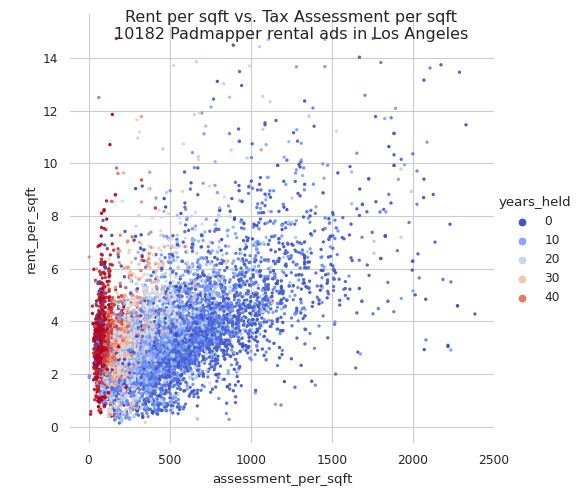
I’ve decided to move my political blogging to a different site, https://prop13.wtf. Check it out! All kinds of cool stuff like tax assessments vs. rent in Los Angeles:
-
Enable HTTPS for S3, Cloudfront, Namecheap
I finally got around to enabling https here. Some notes:
-
Namecheap sells ssl certs via PositiveSSL/Comodo. I thought this would be easiest but they don’t really work with AWS.
- I’ll never get that $7 back
- It’s more work to import a 3rd party certificate vs. creating one on AWS
- After importing the 3rd party certificate (which has to happen in N. Virgina) AWS still claims that it’s not from a trusted source
- Other CNAME gotchas
-
Amazon Certificate Manager allows one to create the certificate from AWS for free
- They’ll auto generate the Route 53 CNAME rules for you
- Still the same weird thing about how you need to do this in N. Virginia even if the rest of you site is elsewhere
-
You need to add an “alias” rule to point your custom domain at Cloudfront.
I found this blog helpful
-
-
Migrating off s3_website.yml
First post in 5+ years! I used to use s3_website to publish this blog. Turns out that project has been deprecated with nothing to replace it. Oh well.
Following this I’ve managed to setup Github Actions to build/deploy the blog. A few small changes:
-
One thousand captcha photos organized with a neural network
Coauthored with Habib Talavati. Originally published on the Clarifai blog at https://blog.clarifai.com/one-thousand-captcha-photos-organized-with-a-neural-network-2/
The below image shows 1024 of the captcha photos used in “I’m not a human: Breaking the Google reCAPTCHA” by Sivakorn, Polakis, and Keromytis arranged on a 32x32 grid in such a way that visually-similar photos appear in close proximity to each other on the grid.

-
My talk at the NYC Machine Learning meetup
Check out this video of my talk at the NYC Machine Learning meetup.
-
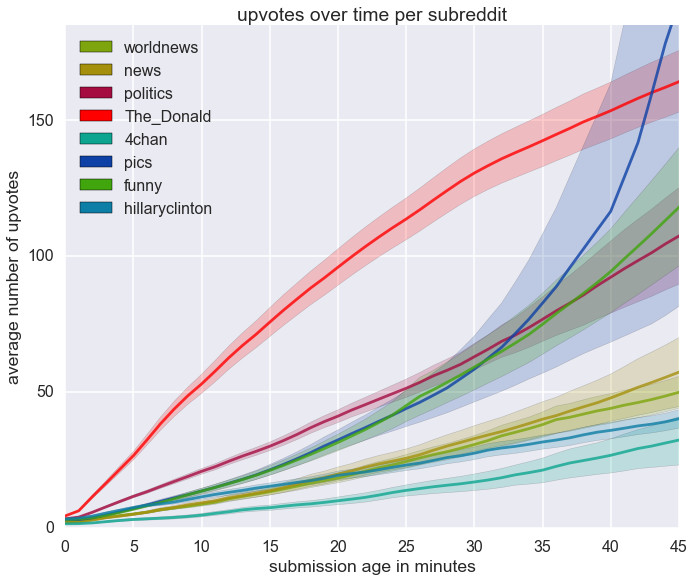
Upvotes over time by subreddit or: Why /r/The_Donald is always on the front page
Here’s a plot of the cumulative number of upvotes per minute for submissions to a few major subreddits:
-
Taxi Strava
Last year Chris Whong used a foil request to obtain a dataset with information on the locations, times, and medallions for 173 million NYC cab rides. I’m interested is determining which cabs are the fastest cabs are and how quickly they can get between various parts of the city.
-
What convolutional neural networks look at when they look at nudity
Originally published on the Clarifai blog at http://blog.clarifai.com/what-convolutional-neural-networks-see-at-when-they-see-nudity/
Last week at Clarifai we formally announced our Not Safe for Work (NSFW) adult content recognition model. Automating the discovery of nude pictures has been a central problem in computer vision for over two decades now and, because of it’s rich history and straightforward goal, serves as a great example of how the field has evolved. In this blog post, I’ll use the problem of nudity detection to illustrate how training modern convolutional neural networks (convnets) differs from research done in the past.

(Warning & Disclaimer: This post contains visualizations of nudity for scientific purposes. Read no further if you are under the age of 18 or if you are offended by nudity.)
-
Darknet Market Basket Analysis
The Evolution darknet marketplace was an online black market which operated from January 2014 until Wednesday of last week when it suddenly disappeared. A few days later, in a reddit post, gwern released a torrent containing daily wget crawls of the site dating back to its inception. I ran some off-the-shelf affinity analysis on the dataset – here’s what I found:
Products can be categorized based on who sells them
On Evolution there are a few top-level categories (“Drugs”, “Digital Goods”, “Fraud Related” etc.) which are subdivided into product-specific pages. Each page contains several listings by various vendors.
I built a graph between products based on vendor co-occurrence relationships, i.e. each node corresponds to a product with edge weights defined by the number of vendors who sell both incident products. So, for example, if there are 3 vendors selling both mescaline and 4-AcO-DMT then my graph has an edge with weight 3 between the mescaline and 4-AcO-DMT nodes. I used graph-tool’s implementation of stochastic block model-based hierarchal edge bundling to generate the below visualization of the Evolution product network:
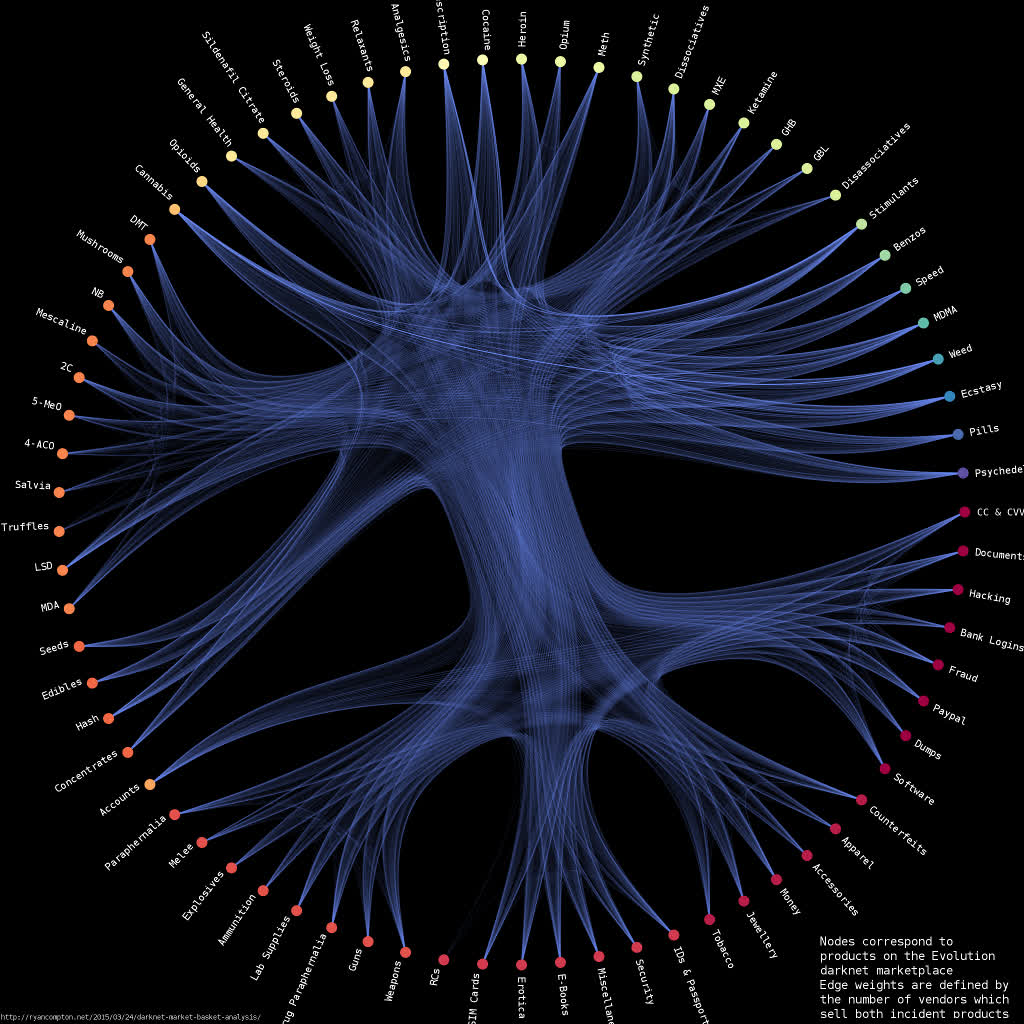
The graph is available in graphml format here. It contains 73 nodes and 2,219 edges (I found a total of 3,785 vendors in the data).
Edges with higher weights are drawn more brightly. Nodes are clustered with a stochastic block model and nodes within the same cluster are assigned the same color. There is a clear division between the clusters on the top half of the graph (correpsonding to drugs) and the clusters on the bottom half (corresponding to non-drugs, i.e. weapons/hacking/credit cards/etc.). This suggests that vendors who sold drugs were not as likely to sell non-drugs and vice versa.
-
Paper update: Geotagging One Hundred Million Twitter Accounts with Total Variation Minimization
Press coverage (updated 2015-05-02):
- Forbes
- Business Insider
- New York Observer
- Schneier on Security
- Daily Caller
- Komando
- UCLA math website
- MIT Tech Review junior varsity
- Serene Risc Quarterly Digest
Earlier this week I updated a paper on the arxiv: http://arxiv.org/abs/1404.7152. The paper appeared a few months ago at IEEE BigData 2014 and was the subject of all my talks last year. This update syncs the arxiv paper with what was accepted for the conference. Here’s the abstract:
Geographically annotated social media is extremely valuable for modern information retrieval. However, when researchers can only access publicly-visible data, one quickly finds that social media users rarely publish location information. In this work, we provide a method which can geolocate the overwhelming majority of active Twitter users, independent of their location sharing preferences, using only publicly-visible Twitter data.
Our method infers an unknown user’s location by examining their friend’s locations. We frame the geotagging problem as an optimization over a social network with a total variation-based objective and provide a scalable and distributed algorithm for its solution. Furthermore, we show how a robust estimate of the geographic dispersion of each user’s ego network can be used as a per-user accuracy measure which is effective at removing outlying errors.
Leave-many-out evaluation shows that our method is able to infer location for 101,846,236 Twitter users at a median error of 6.38 km, allowing us to geotag over 80% of public tweets.
-
Studying automotive sensor data with Open Torque Viewer
I’ve been using Open Torque Viewer combined with the Torque App and a basic OBDII bluetooth sensor to log my car’s sensor data over the past month and a half. Here are a few things that I’ve learned:
Tapping into your car’s ECU is surprisingly easy
All cars sold in North America since 1996 are required to support OBD-II diagnostics with standardized data link connectors and parameter IDs. This is useful, for example, for state-mandated emissions inspections. The OBDII port looks a bit like a VGA connector and, on my car (a 2003 Suzuki Aerio SX), is located under the dash and just above the accelerator.


Attach a bluetooth OBDII device to the port, download the Torque app, setup Open Torque Viewer (I used an EC2 microinstance), and you’ll be able to log each trips data and display it inside of a nice interface. You can also learn about engine fault codes with this setup - I haven’t had any yet.
City mpg estimates are spot on for LA
Torque provides readouts of instantaneous mpg data while you drive. I histogrammed this data and compared it with advertised values in the chart below.
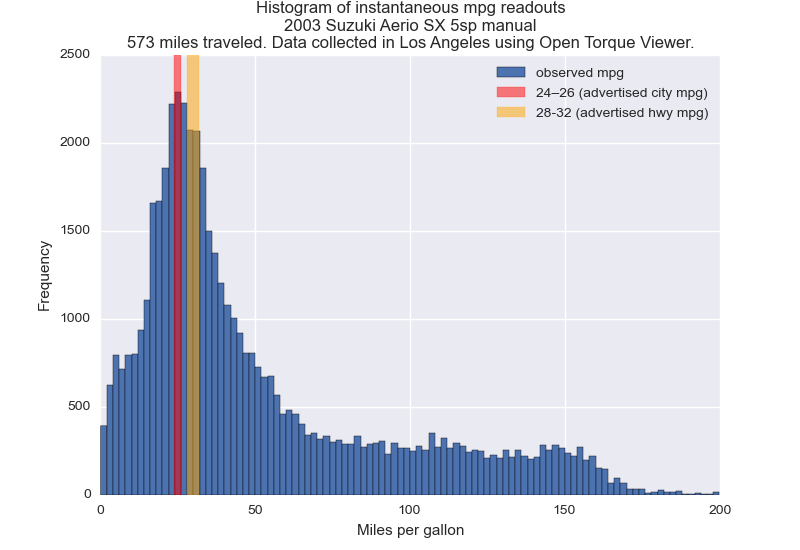
My driving fit the “city” profile reasonably well (even though I’m usually on a “freeway”). I was surprised that I was anywhere near the expected mpg given how unpredictable traffic is. Maybe the fact that Los Angeles is mostly flat and has rainless 75° weather year round evens things out.
-
New Paper: Network-Based Group Account Classification.
Update 2015-03-25: We just got nominated for a best paper award!
Update 2015-04-01: We won best paper!
Patrick Park and I recently got our paper accepted into SBP 2015. The work demonstrates how the structure of Twitter @mention networks can be used to distinguish between accounts owned by individuals or groups. Here’s the abstract
We propose a classification method for group vs. individual accounts on Twitter, based solely on communication network characteristics. While such a language-agnostic, network-based approach has been used in the past, this paper motivates the task from firmly established theories of human interactional constraints from cognitive science to sociology. Time, cognitive, and social role constraints limit the extent to which individuals can maintain social ties. These constraints are expressed in observable network metrics at the node (i.e. account) level which we identify and exploit for inferring group accounts.
-
Url extraction in python
I was looking for a way to identify urls in text and eventually found this huge regex http://daringfireball.net/2010/07/improved_regex_for_matching_urls . I figured I’ll need to do this again so I stuck all that into urlmarker.py and now I can just import it.
import urlmarker import re text = """ The regex patterns in this gist are intended only to match web URLs -- http, https, and naked domains like "example.com". For a pattern that attempts to match all URLs, regardless of protocol, see: https://gist.github.com/gruber/249502 """ print(re.findall(urlmarker.WEB_URL_REGEX,text))will show
['example.com', 'https://gist.github.com/gruber/249502'] -
Hearddit
Hearddit is a Soundcloud/Spotify/reddit bot that builds playlists from links posted on music subreddits. I built the bot since I was getting tired of the twenty or so tracks that the internet radio collaborative filters decided I liked and wanted an easy way to find new music using existing apps.
Here are the playlists:
Hearddit has been running for a little over one week and it’s already discovered some great stuff:
The whole thing is a short python program, available here. It runs every couple of hours so there will be some delay between when a link gets posted on Reddit and when it appears in a playlist.
-
Stochastic block model based edge bundles in graph-tool
Here’s a plot of the political blogging network in “The political blogosphere and the 2004 US Election” but with the edge bundles determined using a stochastic block model (remark: the below plot is the same (ie. same layout and data) as fig. 5 in Tiago’s paper - I just put a black background on it).
The edge-color scheme is the same as in the original paper by Adamic and Glance, i.e. each node corresponds to a blog url and the colors reflect political orientation, red for conservative, and blue for liberal. Orange edges go from liberal blogs to conservative blogs, and purple ones from conservative to liberal (cf fig. 1 in Adamic and Glance).

Code and high-res version here:
-
graph-tool's visualization is pretty good
Here’s a plot of the political blogging network described by Adamic and Glance in “The political blogosphere and the 2004 US Election”. The layout is determined using graph-tool’s implementation of hierarchal edge bundles. The color scheme is the same as in the original paper, i.e. each node corresponds to a blog url and the colors reflect political orientation, red for conservative, and blue for liberal. Orange edges go from liberal blogs to conservative blogs, and purple ones from conservative to liberal (cf fig. 1 in Adamic and Glance). All 1,490 nodes and 19,090 edges are drawn.

The url of each blog is drawn alongside each node, here’s a close-up:

-
Community detection and colored plotting in networkx
Just came across this very easy library for community detection https://sites.google.com/site/findcommunities/ https://bitbucket.org/taynaud/python-louvain/src. Here’s how to create a graph, detect communities in it, and then visualize with nodes colored by their community in less than 10 lines of python:
import networkx as nx import community G = nx.random_graphs.powerlaw_cluster_graph(300, 1, .4) part = community.best_partition(G) values = [part.get(node) for node in G.nodes()] nx.draw_spring(G, cmap = plt.get_cmap('jet'), node_color = values, node_size=30, with_labels=False)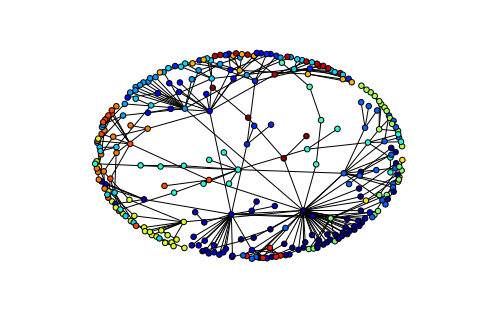
It’s easy to get modularity to:
mod = community.modularity(part,G) print("modularity:", mod)gave
modularity: 0.8700238252368541. -
Rush Hour Surf Report updated
A few minor bug fixes were in order since Twitter started requiring SSL to access their API (which happened in January, meaning my app has been broken for 6 months now…). Get a copy of the only app that makes it so easy to surf report that you can do it from your car! https://play.google.com/store/apps/details?id=com.rcompton.rhsr
Update: app no longer available
-
New Paper: Inferring the Geographic Focus of Online Documents from Social Media Sharing Patterns
I recently published a paper on the arxiv: http://arxiv.org/abs/1406.2392, earlier this month it was accepted into the ChASM workshop at WebSci. Here’s the abstract:
Determining the geographic focus of digital media is an essential first step for modern geographic information retrieval. However, publicly-visible location annotations are remarkably sparse in online data. In this work, we demonstrate a method which infers the geographic focus of an online document by examining the locations of Twitter users who share links to the document. We apply our geotagging technique to multiple datasets built from different content: manually-annotated news articles, GDELT, YouTube, Flickr, Twitter, and Tumblr.
-
Infinite Jest by the numbers
After stressing my reading comprehension over the past eight months I’ve finally finished David Foster Wallace’s Infinite Jest. The writing is, in a word, impressive. Wallace’s command of the English language allows him to do things that I’ve never seen before. In this post I’ll try to quantify a few of the stylistic features that I think really stood out.
First off, to run these experiments, one needs an electronic version of the book. It turns out that these are remarkably easy to find online. I ran the .pdf here through pdftotext, imported nltk, and got these results:
“But and so and but so” is the longest uninterrupted chain of conjunctions
In Infinite Jest conjunctions often appear in chains of length three or greater. There is a length-six chain on page 379 of the .pdf. It’s due to a minor character, “old Mikey”, standing at the Boston AA podium and speaking to a crowd:
I’m wanting to light my cunt of a sister up so bad I can’t hardly see to get the truck off the lawn and leave. But and so and but so I’m driving back home, and I’m so mad I all of a sudden try and pray.
Now, according to Wiktionary, there are 224 conjunctions in the English language. It’s possible to quickly get all of them by entering this query into DBpedia’s public Wiktionary endpoint:
PREFIX terms:<http://wiktionary.dbpedia.org/terms/> PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#> PREFIX dc:<http://purl.org/dc/elements/1.1/> SELECT DISTINCT(?label) WHERE { ?x terms:hasPoS terms:Conjunction . ?x dc:language terms:English . ?x rdfs:label ?label . }With this list we can find the most common uninterrupted conjunction chains along with the number of times they appeared in the text:
Conjunction Triples Conjunction Quadruples Conjunction Quintuples and / or : 23 not until then that : 1 but so but then so : 1 whether or not : 9 so and but that : 1 and not only that but : 1 and then but : 8 not only that but : 1 and so and but so : 1 and but so : 6 so then but so : 1 and then when : 6 but so but then : 1 and that if : 5 and where and when : 1 and then only : 5 and but then when : 1 and but then : 5 and but so why : 1 and then if : 5 and so but since : 1 if and when : 5 but not until after : 1 (Remark: according to Wiktionary, “/” is a valid conjunction)
-
Bit-reversal permutation in Python
For the FFT sonification I needed to implement my own FFT in order to keep track of which notes are being played while the Fourier transform executes. It turns out that implementing an FFT isn’t too difficult as long as you don’t care how fast it goes (Note: if you do need it to be fast you’ll have a hard time beating fftw which “is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize performance” (cf http://www.fftw.org/fftw-paper-ieee.pdf) ).
The key ingredient to implementing an FFT with the Cooley-Tukey algorithm (which I used for the sonification) is a traversal of the input array in bit-reversed order. Here’s how I did the traversal in Python:
def bit_reverse_traverse(a): n = a.shape[0] assert(not n&(n-1) ) # assert that n is a power of 2 if n == 1: yield a[0] else: even_index = arange(n/2)*2 odd_index = arange(n/2)*2 + 1 for even in bit_reverse_traverse(a[even_index]): yield even for odd in bit_reverse_traverse(a[odd_index]): yield oddWhat I thought was interesting about this code was that I had to use Python’s
yieldstatement, which I had never run into before. -
New Paper: Prediction of Foreign Box Office Revenues Based on Wikipedia Page Activity
Brian and I recently published a paper on the arxiv: http://arxiv.org/abs/1405.5924, earlier this month it was accepted into the ChASM workshop at WebSci. Here’s the abstract:
A number of attempts have been made at estimating the amount of box office revenue a film will generate during its opening weekend. One such attempt makes extensive use of the number of views a film’s Wikipedia page has attracted as a predictor of box office success in the United States. In this paper we develop a similar method of approximating box office success. We test our method using 325 films from the United States and then apply it to films from four foreign markets: Japan (95 films), Australia (118 films), Germany (105 films), and the United Kingdom (141 films). We find the technique to have inconsistent performance in these nations. While it makes relatively accurate predictions for the United States and Australia, its predictions in the remaining markets are not accurate enough to be useful.
-
Storing a Kryo object in a compiled jar
This really threw me off for a while (cf https://stackoverflow.com/questions/23748254/storing-a-kryo-object-in-a-compiled-jar ).
I had a
HashMapI needed to persist and have fast access to. I used Kryo to serialize the objectKryo kryo = new Kryo(); MapSerializer serializer = new MapSerializer(); kryo.register(Location.class); kryo.register(HashMap.class, serializer); Output output = new Output(new FileOutputStream("src/main/resources/locations50K.kryo")); kryo.writeObject(output, locationMap); output.close(); -
New Paper: Geotagging One Hundred Million Twitter Accounts with Total Variation Minimization
I recently published a paper on the arxiv: http://arxiv.org/abs/1404.7152, and it made Tech Review junior varsity! Here’s the abstract:
Geographically annotated social media is extremely valuable for modern information retrieval. However, when researchers can only access publicly-visible data, one quickly finds that social media users rarely publish location information. In this work, we provide a method which can geolocate the overwhelming majority of active Twitter users, independent of their location sharing preferences, using only publicly-visible Twitter data.
Our method infers an unknown user’s location by examining their friend’s locations. We frame the geotagging problem as an optimization over a social network with a total variation-based objective and provide a scalable and distributed algorithm for its solution. Furthermore, we show how a robust estimate of the geographic dispersion of each user’s ego network can be used as a per-user accuracy measure, allowing us to discard poor location inferences and control the overall error of our approach.
Leave-many-out evaluation shows that our method is able to infer location for 101,846,236 Twitter users at a median error of 6.33 km, allowing us to geotag roughly 89% of public tweets.
-
Algorithm Sonification III: The FFT
Originally published in 2009 at http://www.math.ucla.edu/~rcompton/fft_sonification/fft_sonification.html
The FFT is an essential tool for digital signal processing and electronic music production. It is easily, commonly, and inefficiently implemented via the recursive Cooley-Tukey algorithm which we now briefly review.
To compute the discrete Fourier transform, \(\{ X_k \}_{k=0}^{N-1}\), of a sequence, \(\{ x_n \}_{n=0}^{N-1}\), we must sum
\[\begin{equation*} X_k = \sum_{n=0}^{N-1} x_n e^{\frac{-2 \pi i}{N}nk} \end{equation*}\]for each $k$ in $0, …, N-1$. Using the Danielson-Lanczos lemma, we split the above sum into its even and odd constituents
\[\begin{eqnarray*} X_k &=& \sum_{n=0}^{N/2-1} x_{2n} e^{\frac{-2 \pi i}{N}(2n)k} + \sum_{n=0}^{N/2-1} x_{2n+1} e^{\frac{-2 \pi i}{N}(2n+1)k} \\ &=& X_{\text{even }k} + e^{\frac{-2 \pi i}{N}k} X_{\text{odd }k} \end{eqnarray*}\] -
Algorithm Sonification II: Gauss Seidel method
Originally published in 2009 at http://www.math.ucla.edu/~rcompton/musical_gauss_seidel/musical_gauss_seidel.html
One second of a 44.1kHz single channel .wav file can be read into an array (call it b) of length 44100. Given a matrix A we seek solutions to the system Ax=b. Through iterations of Gauss-Seidel the vector Ax will approach b with the high frequency parts of Ax getting close to b first. If we take b to be a song recording, some white noise as our initial guess and write out Ax at each iteration we observe that the high pitched notes in b become audible first while at the same time the pitch of the white noise decreases.
Audio of the initial 12 second .wav file (white noise) initialAx.wav
-
Algorithm Sonification I: Sorting
Originally published in 2009 at http://www.math.ucla.edu/~rcompton/musical_sorting_algorithms/musical_sorting_algorithms.html
Suppose you drop a set of drums and they land randomly ordered in a row on the floor. You want to put the drums back in order but can only pick up and swap two at a time. A good strategy to minimize the number of swaps you must make is to follow the Quicksort algorithim http://en.wikipedia.org/wiki/Quicksort.
If you order the drums by their general MIDI number and simultaneously strike any two which you swap then you will produce a sound similar to this:
-
Sample pom.xml to build Scala *-jar-with-dependencies.jar
I’ve been using Spark for a few months now. It’s great for tasks that don’t fit easily into a Pig script. If you’ve already been writing Java for a while it can be a drag to switch everything over to sbt just for Spark.
Here’s a basic pom.xml that can build scala code (you’ll need maven 3) and include all dependencies into one giant jar.
-
Supervised Learning Superstitions Cheat Sheet
This notebook contains notes and beliefs about several commonly-used supervised learning algorithms. My dream is that it will be useful as a quick reference or for people who are irrational about studying for machine learning interviews.
The methods discussed are:
- Logistic regression
- Decision trees
- Support vector machines
- K-nearest neighbors
- Naive Bayes
To see how different classifiers perform on datasets of varying quality I’ve plotted empirical decisions boundaries after training each classifier on “two moons”. For example, here’s what happens to scikit-learn’s decision tree (which uses a version of the CART algorithm) at different noise levels and training sizes:
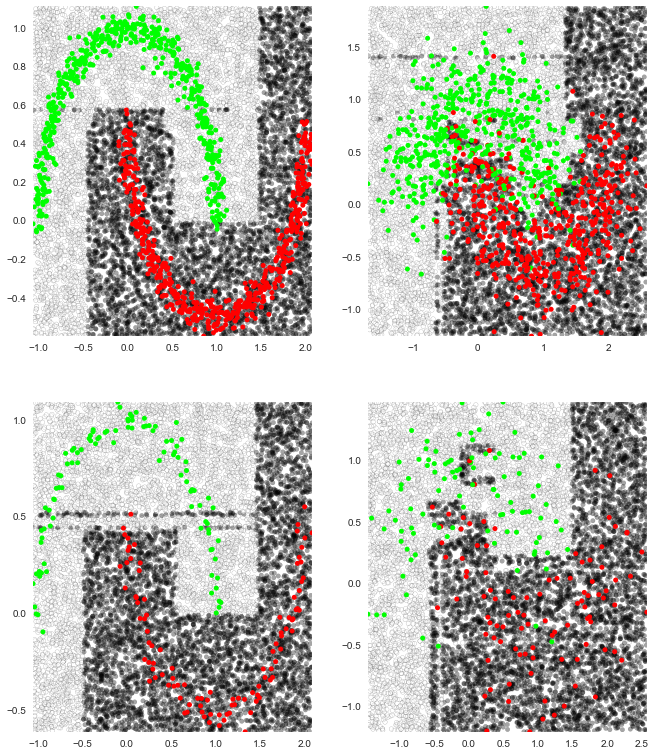
Here’s the notebook: http://ryancompton.net/assets/ml_cheat_sheet/supervised_learning.html
(as a .ipynb file: http://ryancompton.net/assets/ml_cheat_sheet/supervised_learning.ipynb)